Lambda internals (Part one)


The past several years have seen a significant rise in the use of serverless cloud computing solutions, and with good reason. Serverless applications can be cheaper, more scalable, more rapidly developed and have introduced a new landscape for both developers and attackers alike. For attackers, the world of compromising a static endpoint system and persisting until remediation is changing. Now, targets may be containers or serverless functions that are ephemeral, requiring new methods to stay persistent within the environment.
Part one of this blog series discusses the current internals of AWS Lambda; part two details how attackers might use its implementation to compromise customer environments.
AWS Lambda is a serverless solution that allows applications to execute code on-demand without charging customers for idle time. The AWS Lambda service sets up and invokes Lambda functions on-demand in an execution environment. As shown in Figure 1, a Lambda execution environment consists of four important components: Rapid, the Rapid API, Lambda functions and corresponding runtimes, and Lambda extensions. At a high level, Rapid is responsible for brokering communication between customer runtime code and core AWS services. This post examines each component in more detail.
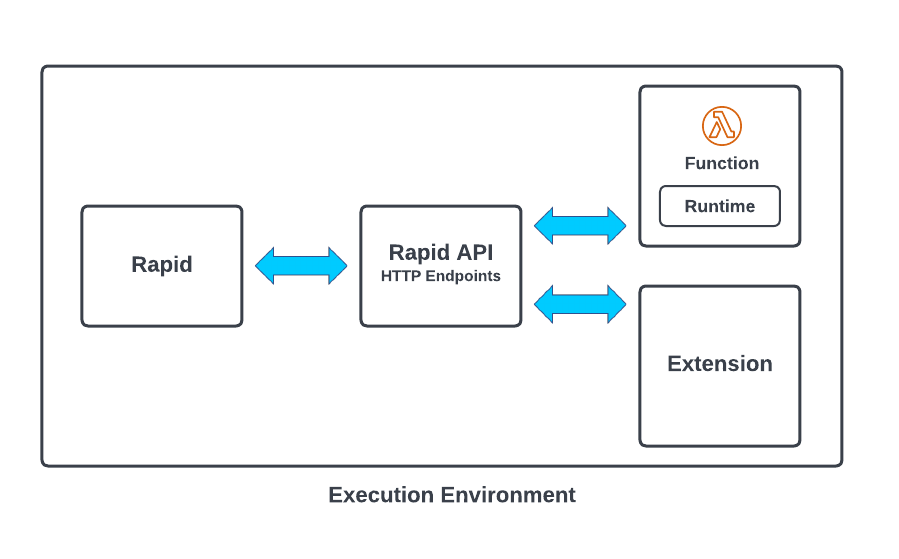
Exploring the execution environment
In this section, we’ll dive into the execution environment, starting with how the environment is created. Next, we’ll explore “Rapid”, the runtime, layers and extensions, and briefly discuss the filesystem and environment variables.
Creating the execution environment
The physical machines implementing Lambda run the opensource microVM orchestration framework named Firecracker. Firecracker uses KVM to create “microVM”s. When needed, Lambda allocates an execution environment for either the ARM64 or AMD64 architectures. AWS documentation states that execution environments are not re-used between customers.
These AWS provisioned containers run a variant of Amazon Linux 2 with a kernel version of 4.14 and all processes run with the permissions of a default user named “sbx_user1051”.
Each Lambda instance is booted with a single, custom init process (PID 1) that is responsible for bootstrapping the rest of the Lambda execution environment. This init process is written in Go and referred to in source code as “rapid” (Rapid).
Rapid
Rapid is responsible for brokering communication between customer runtime code and core AWS services. Rapid is written in Go and is partially open source as part of the AWS Lambda emulation project.
As shown in Figure 1, runtimes communicate with the Rapid process through a local HTTP server (Rapid API), served from Rapid itself, as a form of Local Inter-Process Communication (LPC). The server and port for this server is defined by a reserved environment variable named AWS_LAMBDA_RUNTIME_API and typically is set to “http://127.0.0.1:9001”. Runtimes receive new Lambda invocation events by sending requests to the Rapid API. Once events are processed, runtimes are expected to post an HTTP response to this same endpoint. Rapid exposes multiple HTTP endpoints that allow runtimes and extensions to receive events and send responses. Table 1 shows some of the HTTP endpoints for the Rapid API.
| Endpoint | Description |
|---|---|
| /2018-06-01/runtime/invocation/next | Retrieves the next Lambda invocation event. This returns the raw event payload used in the Lambda invocation. |
| /2020-01-01/extension/event/next | Retrieves the next Lambda extension event. |
| /2018-06-01/runtime/invocation/{awsrequestid}/response | Posts the return value from the Lambda function handler. |
| /2018-06-01/runtime/invocation/{awsrequestid}/error | Used by the runtime to report errors during execution. |
| /2020-01-01/extension/register | Used by extensions to register themselves for extension events (INIT, INVOKE, SHUTDOWN). |
| /2020-01-01/extension/init/error | Extensions report errors during init here. |
| /2020-01-01/extension/exit/error | Extensions report errors during exit here. |
| /2020-08-15/logs | Extensions use this endpoint to subscribe to the runtime log stream for additional processing. |
In addition to the Rapid API, Rapid opens file descriptors to sockets that are presumably used to communicate outside of the container to AWS core services. Figure 2 below shows a snapshot of the open file descriptors in a test environment. Further research is needed to determine the scope and function of each socket.
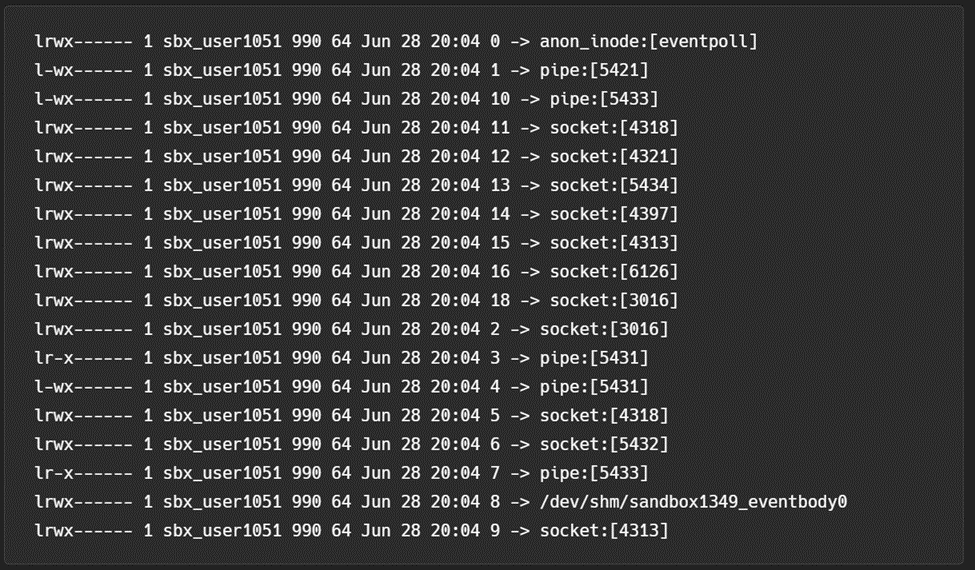
Several of these file descriptors are referenced in internal environment variables that are not inheritable by other processes in the environment via the FD_CLOEXEC flag. These variables are briefly mentioned in older code in the Lambda emulation framework but otherwise, are completely undocumented and shown below in Table 2. These variables are all set to file descriptor integers and are likely passed in directly to the container from the host OS.
| Environment variable name |
|---|
| _LAMBDA_TELEMETRY_LOG_FD |
| _LAMBDA_LOG_FD |
| _LAMBDA_SHARED_MEM_FD |
| _LAMBDA_CONSOLE_SOCKET |
| _LAMBDA_CONTROL_SOCKET |
| _LAMBDA_DIRECT_INVOKE_SOCKET |
Memory layout
The memory layout of Rapid is relatively standard for a Go process except for the shared memory section mentioned above. Figure 4 shows the memory map layout.
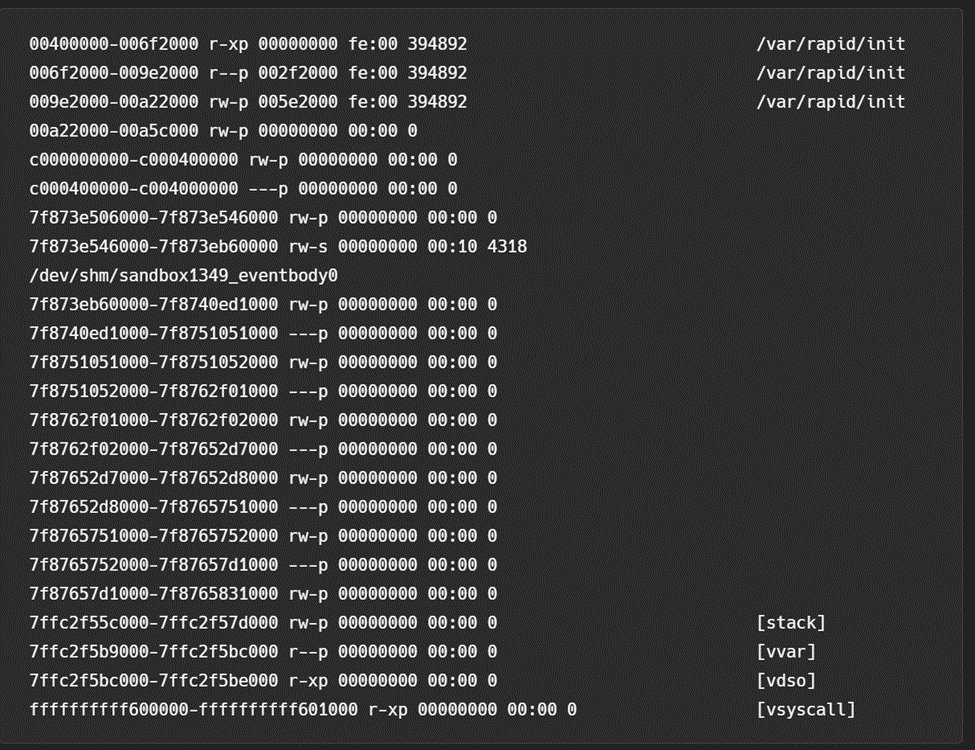
That said, there are at least two important items of note. First, Rapid runs as the same user as the runtime and all extensions. Second, the default kernel is compiled with both the “process_vm_readv” and “process_vm_writev” system calls. In combination, these items allow all processes within the Lambda execution environment to arbitrarily access the memory of all other processes (more on this later).
Runtime
Lambda supports different programming languages with runtimes. These runtimes provide the basic libraries and interpreters to run code. The Lambda function configuration supports several AWS runtimes. In addition, AWS supports custom, customer-implemented runtimes in any language such as C++ or Rust. The idea is for the runtime to contain only the relevant executables and libraries needed to run customer code. For example, if the Node.js runtime is selected, no Python related binaries are expected to exist.
Each runtime is expected to contain a file named “bootstrap”. This file is typically a Bash script that invokes the main interpreter for the Lambda function code. Amazon has a public GitHub repo demonstrating how runtimes are implemented.
Filesystem
By default, all mounted filesystems are read-only except for the “/tmp” directory. The “/tmp” directory persists between invocations of the same function and is accessible to processes within the environment. When the Lambda is being shut down, everything in “tmp” is “erased”, similar to a normal Docker container. As expected, trying to mount or write to any other location results in a permission error.
The configured runtime is in “/var/runtime” and contains the code needed to invoke the Lambda function. In addition, all bootstrap code is located here and is directly executed by Rapid, located at “/var/init/rapid”.
The “/opt” directory is reserved for Lambda Layers where arbitrary code can be added by any AWS account. Extensions are expected to be located at /opt/extensions/<extension_name>.
The kernel’s virtual file system (VFS) is mounted similar to a dockerized Linux system. “/dev” is minimal and contains basic devices needed by the runtime and is shown in Figure 4.

Environment variables
Environment variables are key to the Lambda execution environment. These variables drive many important aspects of the execution runtime. For example, one variable informs the bootstrapper where on-disk relevant code is located.
Normally, customers can set these variables using the AWS Dashboard or the UpdateFunctionConfiguration API. That said, there are protected variables used internally by Lambda that cannot be updated. Many of these variables are documented by Amazon here.
Although there are many environment variables, a subset contributes to the execution of code within the execution environment. Table 3 shows a subset of these default environment variables.
| Environment variable name | Description |
|---|---|
| _HANDLER | The name of the function for the runtime to execute (e.g. lambda_function.lambda_handler) |
| AWS_EXECUTION_ENV | The type of execution environment |
| AWS_LAMBDA_FUNCTION_NAME | The name assigned to the function |
| AWS_LAMBDA_RUNTIME_API | IP and port number of the Rapid API server |
| LAMBDA_TASK_ROOT | Points to a directory containing the customer code that will be executed |
| LAMBDA_RUNTIME_DIR | Points to a directory containing libraries needed by the configured runtime |
| AWS_LAMBDA_EXEC_WRAPPER | Specifies a script as an internal extension that can be used to wrap the initialization of the relevant runtime |
Lambda layers and extensions
AWS Lambda provides two additional mechanisms for deploying code with Lambda functions; Layers and Extensions.
Layers enable AWS developers to factor common code out of each Lambda function and create a package to re-use or share. Layers can be published and shared publicly with all AWS customers.
Extensions enable AWS developers to extend their existing Lambda function without modifying the Lambda function itself. Amazon defines two types of extensions: internal and external.
Internal extensions
Internal extensions are an AWS supported mechanism to control the bootstrap process. By specifying the environment variable “AWS_LAMBDA_EXEC_WRAPPER” to the Lambda function’s configuration, the bootstrap process can be intercepted and modified with an arbitrary script provided either in a layer or as part of the function package. These scripts are heavily dependent on the specific runtime and are responsible for executing the relevant interpreters (Python, Node.js, Ruby, etc.).
External extensions
External extensions are an AWS supported mechanism to augment an existing Lambda function with no code changes to the original Lambda function. External extensions are packaged through AWS layers as zip archives. External extensions, when deployed, are mounted at the “/opt” directory within the Lambda execution environment and are automatically discovered by Rapid and executed before any of the runtime code.
AWS Lambda lifecycle summary
Now that we’ve explored different components of AWS Lambda, Figure 5 summarizes the high-level process from bare metal through processing an event with AWS Lambda.
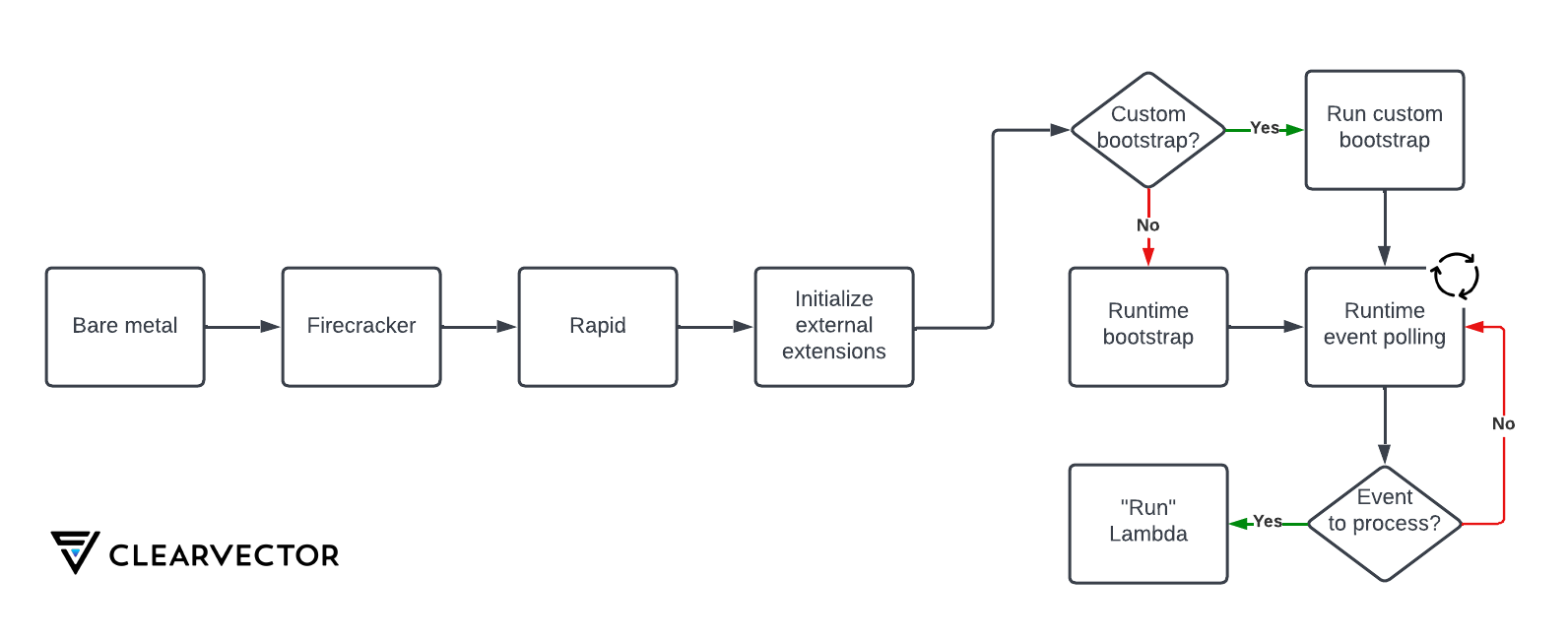
Conclusion
This post provided a high-level overview of the Lambda execution environment and how customer code interacts with the AWS provided infrastructure. In the next post, we examine how an attacker might leverage this architecture.
References for further reading: